
油价、金价,都涨了!这一夜,市场经历了什么?
转自:央视财经(图片来源网络,侵删) 当地时间周五,最新公布的经济数据显示,美国1月生产者价格指数(PPI)与本周稍早公布...

扫一扫用手机浏览
OpenAI 发布文生视频模型 Sora,可遵循用户的指示生成长达一分钟的视频,并保持视觉质量。浙商证券发布研报称,OpenAI 发布 Sora 模型,有望开启多模态大模型的新一轮浪潮。

以下为研报摘要:
近日,OpenAI 发布文生视频模型 Sora,可遵循用户的指示生成长达一分钟的视频,并保持视觉质量;而谷歌发布 Gemini 1.5 Pro 大模型,可支持超长文本上下文推理,并且多模态能力表现优异,可精确捕捉电影视频细节。我们认为在 OpenAI、谷歌的引领下,有望开启多模态大模型的新一轮浪潮。
OpenAI 发布 Sora 文生视频模型,可生成最长一分钟视频
北京时间 2024 年 2 月 16 日,OpenAI 发布文生视频模型 Sora,可遵循用户的指示生成长达一分钟的视频,并保持视觉质量。Sora 能够生成包含多个角色、特定类型的动作以及主体和背景的准确细节的复杂场景。在 OpenAI 官网上可看到多个由 Sora 模型生成的视频案例,如时尚女子在东京街头、猛犸象在雪原上行走、在艺术馆中边走边欣赏艺术品等等;

Sora 模型基于 DALL-E 和 GPT 模型研究成果,可实现视频加工、拼接等功能
除了基于文本生成视频的能力,Sora 模型也可以接受其他输入,例如预先存在的图像或视频。Sora 能够执行多种图像和视频编辑任务,如创建循环视频、为静态图像添加动画、将视频向前或向后延伸、将两段视频进行拼接等。
OpenAI 官方技术文档指出,研究人员探索了生成模型在视频数据上的大规模训练,并在时长、分辨率和宽高比可变的视频和图像上联合训练了文本条件下的扩散模型。与大语言模型使用文本 Token 不同的是,Sora 模型使用了视觉补丁(Visual Patches)方法,OpenAI 证明了这种视觉补丁的方法在视频/图像生成模型中非常有用。
谷歌发布 Gemini 1.5 Pro 大模型,长文本及多模态推理能力出色

美国时间 2024 年 2 月 15 日,谷歌发布基于 MoE 架构的 Gemini 1.5 Pro 大模型,是基于前期发布的 Gemini 1.0 Pro 的更新版本。大模型在处理 530,000 token 文本时,能够实现 100%的检索完整性,在处理 1,000,000 token 的文本时也可达到 99.7% 的检索完整性。在多模态能力方面,Gemini 1.5 Pro 能够分别在约 11 小时的音频资料和大约 3 小时的视频内容中,100%成功检索到各种隐藏的音频片段或视觉元素。根据谷歌官网信息,Gemini 1.5 Pro 可实现对阿波罗 11 号的 402 页飞行记录、或是 44 分钟的无声电影内容的准确推理。
看好 2024 年多模态大模型以及大模型在 3D 建模、视频领域迎来爆发
我们在 2023 年 11 月 15 日发布的《大地回春,百花齐放——计算机行业 2024 年度策略》中提出,2024 年国内外厂商有望发布更加复杂的多模态大模型,实现文本、语音、图像以及音视频等多模态数据的复杂处理和交互。我们认为 OpenAI 发布 Sora 模型,有望开启多模态大模型的新一轮浪潮。
转自:央视财经(图片来源网络,侵删) 当地时间周五,最新公布的经济数据显示,美国1月生产者价格指数(PPI)与本周稍早公布...
OpenAI 发布文生视频模型 Sora,可遵循用户的指示生成长达一分钟的视频,并保持视觉质量。浙商证券发布研报称,OpenA...
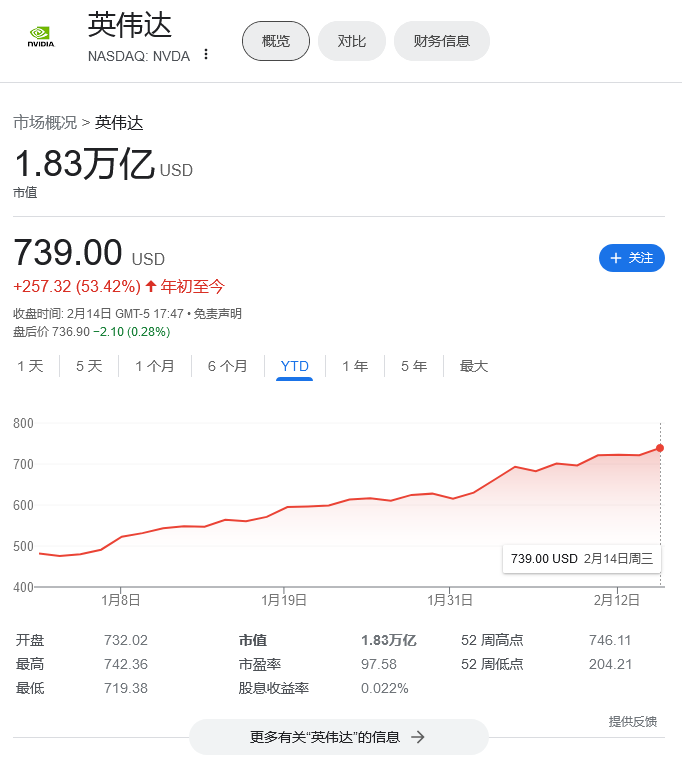
本文源自:IT之家 根据瑞银(UBS)分析师近日分享给投资者的备忘录,英伟达大幅缩短了 AI GPU 的交付周期(即客户下...

来源:东方财富网(图片来源网络,侵删) 日前,在REITs整体行情连涨三日后,有基金公告,年后首个交易日将停牌一小时。 ...
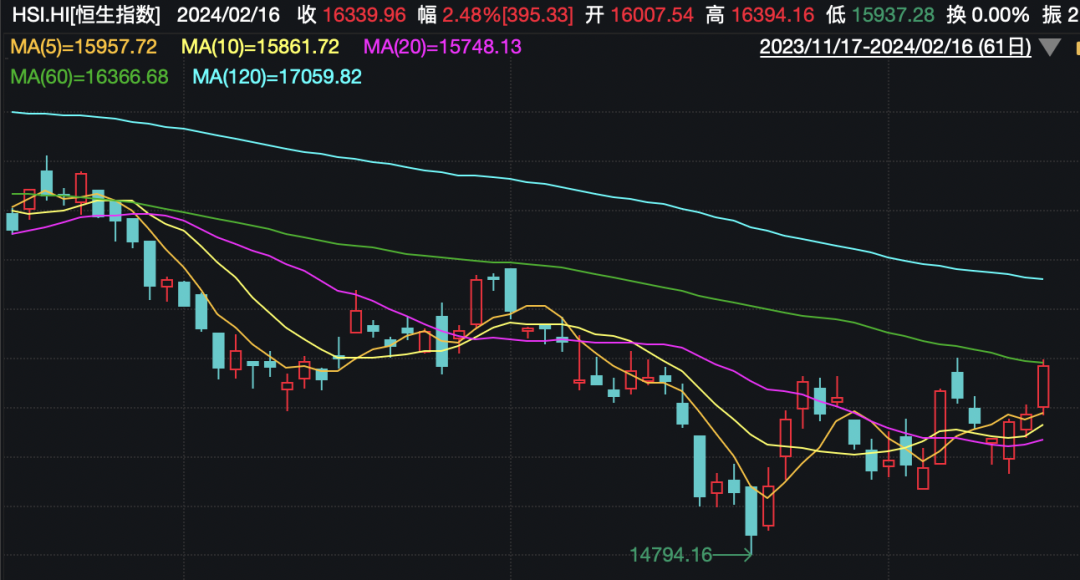
炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会! 2月16日,港股再度大涨,恒生科技指数一度涨超4...

里士满联储行长Thomas Barkin表示,本周早些时候发布的强于预期的通胀数据凸显出为何决策者希望在降息前看到更多数据。(...